
- Published on
Meetings in Minutes - Auto-Summarize Your Meetings with Groq & Streamlit
In this tutorial, we'll walk through building a Streamlit app that allows users to upload an audio or video file, transcribe it using the Groq API, and generate a summary of the content. This app can be very useful for businesses to quickly get the key points from meetings, podcasts or other audio without having to listen to the full recording.
Benefits for Businesses
- Save time - Quickly get the main takeaways from meetings without sitting through the entire audio
- Stay informed - Allows employees to catch up on meetings they may have missed
- Easy knowledge sharing - Transcriptions and summaries can be stored and shared with relevant teams
- Improved documentation - Automatically generate meeting notes and records
App Overview
Here's a high-level overview of how the app works:
- User uploads an audio or video file
- Audio is extracted from video files
- Audio is transcribed using Groq's Speech-to-Text API
- Transcription is summarized using Groq's Text Summarization API
- Transcription and summary are displayed in the app
Implementation
Now let's dive into the code! We'll break it down section by section.
Imports and Setup
import streamlit as st
import os
from groq import Groq
import tempfile
import wave
import io
from moviepy.editor import VideoFileClip
# Initialize the Groq client
client = Groq(api_key="your_api_key")
First we import the necessary libraries:
streamlitfor building the web apposfor file/directory operationsgroqfor calling the Groq APItempfilefor creating temporary fileswaveandiofor audio processingmoviepyfor extracting audio from video files
We initialize the Groq client with our API key. Make sure to use your own API key here.
Custom Theme
st.markdown(
"""
<style>
/* Main background and text colors */
body {
color: #E0E0E0;
background-color: #1E1E1E;
}
.stApp {
background-color: #1E1E1E;
}
/* Headings */
h1, h2, h3 {
color: #BB86FC;
}
/* Buttons */
.stButton>button {
color: #1E1E1E;
background-color: #BB86FC;
border: none;
border-radius: 4px;
padding: 0.5rem 1rem;
font-weight: bold;
}
.stButton>button:hover {
background-color: #A66EFC;
}
/* File uploader */
.stFileUploader {
background-color: #2E2E2E;
border: 1px solid #BB86FC;
border-radius: 4px;
padding: 1rem;
}
/* Audio player */
.stAudio {
background-color: #2E2E2E;
border-radius: 4px;
padding: 0.5rem;
}
/* Text areas (for transcription output) */
.stTextArea textarea {
background-color: #2E2E2E;
color: #E0E0E0;
border: 1px solid #BB86FC;
border-radius: 4px;
}
</style>
""",
unsafe_allow_html=True,
)
This block of code defines a custom dark theme for the app using CSS. It styles the background, text, buttons, file uploader, audio player, and text areas. The unsafe_allow_html=True argument allows rendering the raw HTML.
Transcription Function
def transcribe_audio(audio_file):
with open(audio_file, "rb") as file:
transcription = client.audio.transcriptions.create(
file=(os.path.basename(audio_file), file.read()),
model="whisper-large-v3-turbo",
response_format="json",
language="en",
temperature=0.0,
)
return transcription.text
The transcribe_audio function takes an audio file path, reads the file in binary mode, and sends it to Groq's Speech-to-Text API. It uses the whisper-large-v3-turbo model, specifies English language, and returns the transcription text.
Audio Extraction Function
def extract_audio_from_video(video_file):
with tempfile.NamedTemporaryFile(delete=False, suffix=".mp3") as temp_audio_file:
with VideoFileClip(video_file) as video:
video.audio.write_audiofile(temp_audio_file.name, codec="mp3")
return temp_audio_file.name
For video files, we first need to extract the audio. The extract_audio_from_video function uses moviepy to read the video, extract the audio, and write it to a temporary MP3 file. It returns the path of the temporary audio file.
File Upload and Display
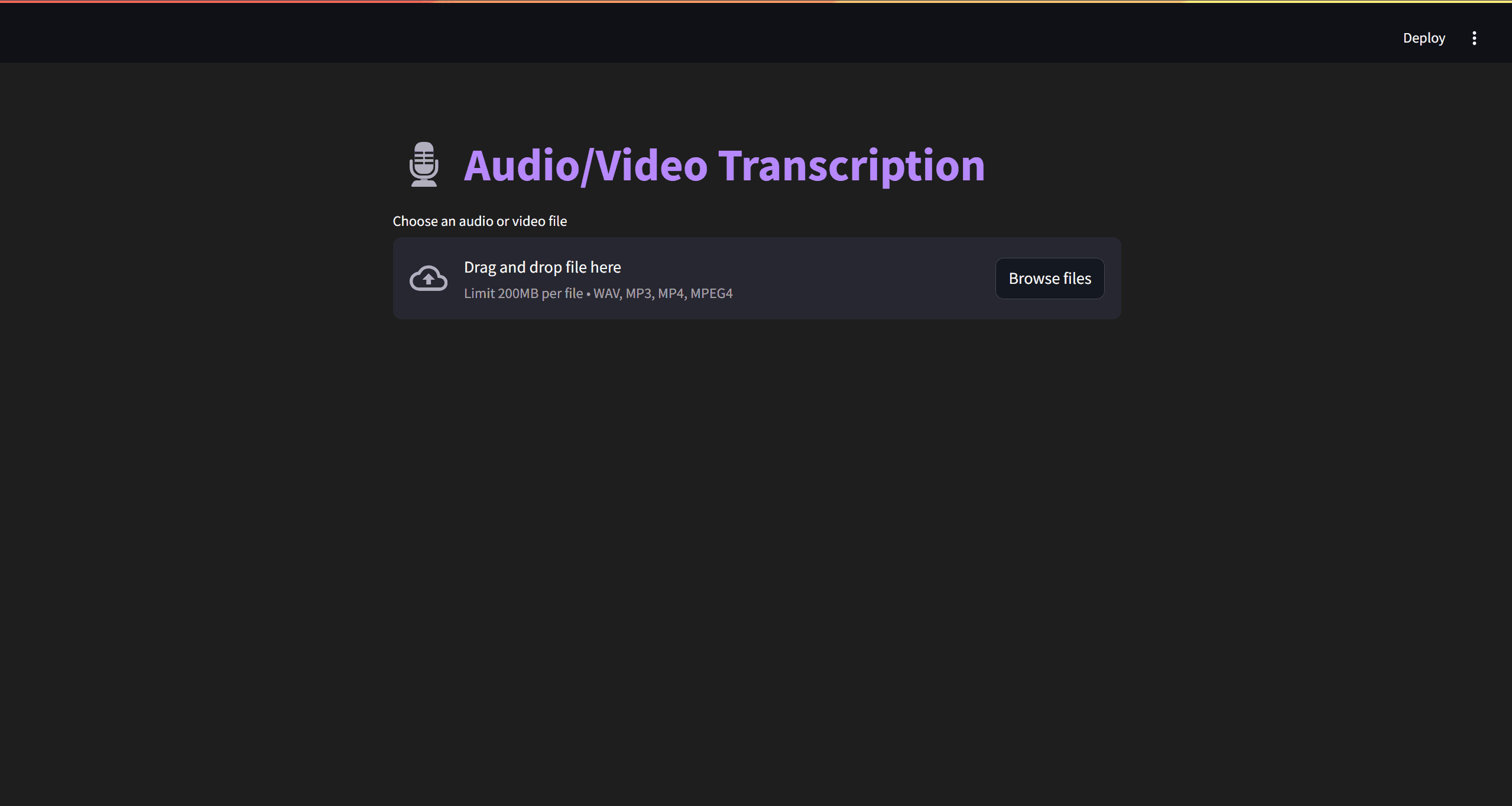
st.title("🎙️ Meeting/Podcast Summarizer")
uploaded_file = st.file_uploader(
"Choose an audio or video file", type=["wav", "mp3", "mp4"]
)
if uploaded_file is not None:
file_bytes = uploaded_file.read()
if uploaded_file.type.startswith("audio"):
st.audio(file_bytes)
elif uploaded_file.type.startswith("video"):
st.audio(file_bytes)
We create a title for the app and a file uploader widget that accepts WAV, MP3, and MP4 files. When a file is uploaded:
- Read the file bytes
- Display an audio player with the file content
Transcription and Summary Buttons
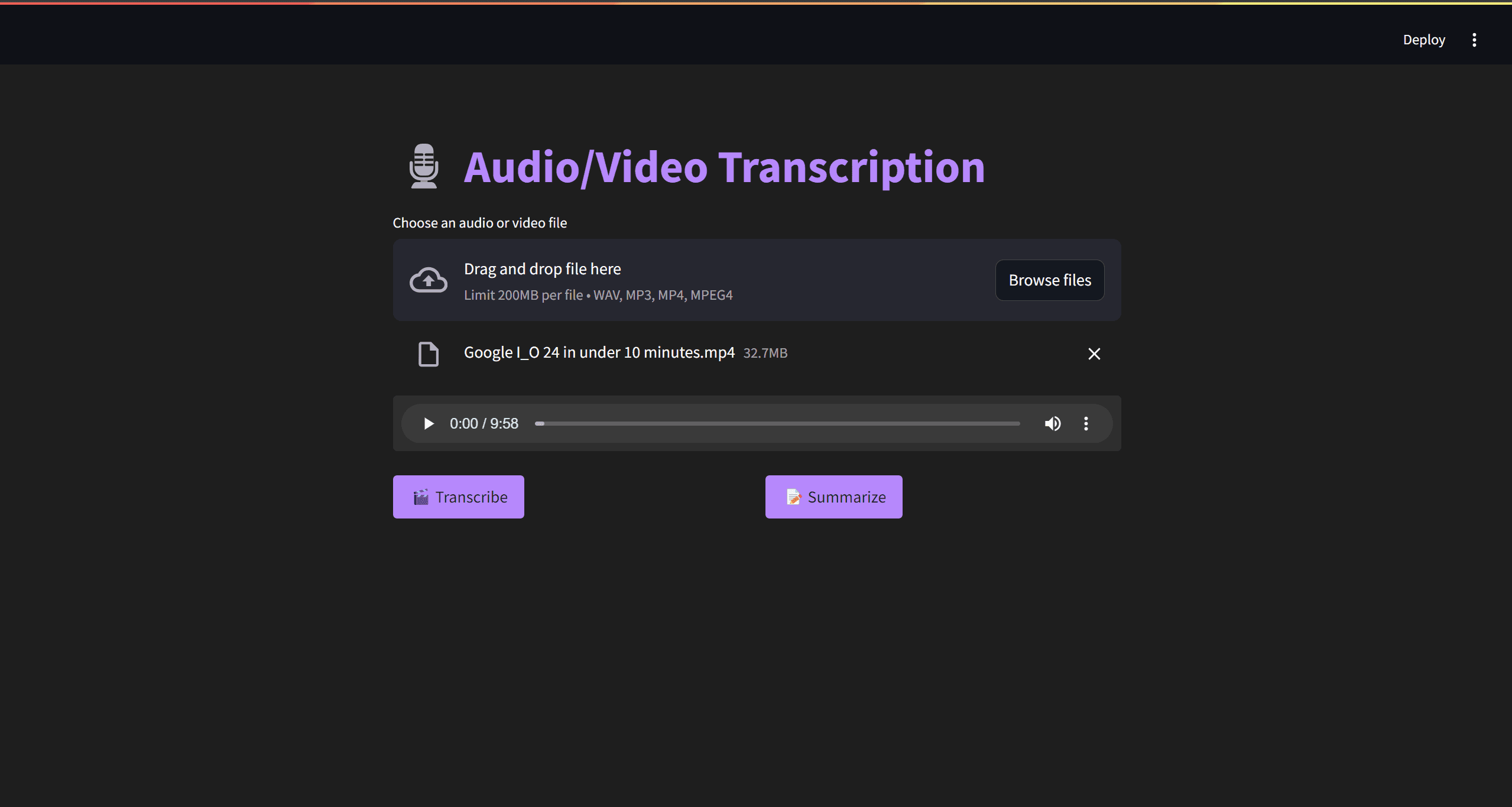
col1, col2 = st.columns(2)
with col1:
transcribe_button = st.button("🎬 Transcribe")
with col2:
summarize_button = st.button("📝 Summarize")
We create two columns with "Transcribe" and "Summarize" buttons. The buttons are created using st.button inside st.columns to lay them out side-by-side.
Transcription
if transcribe_button:
with st.spinner("Transcribing..."):
try:
with tempfile.NamedTemporaryFile(
delete=False, suffix="." + uploaded_file.name.split(".")[-1]
) as temp_file:
temp_file.write(file_bytes)
temp_file_path = temp_file.name
if uploaded_file.type.startswith("video"):
audio_file_path = extract_audio_from_video(temp_file_path)
os.unlink(temp_file_path)
temp_file_path = audio_file_path
transcription = transcribe_audio(temp_file_path)
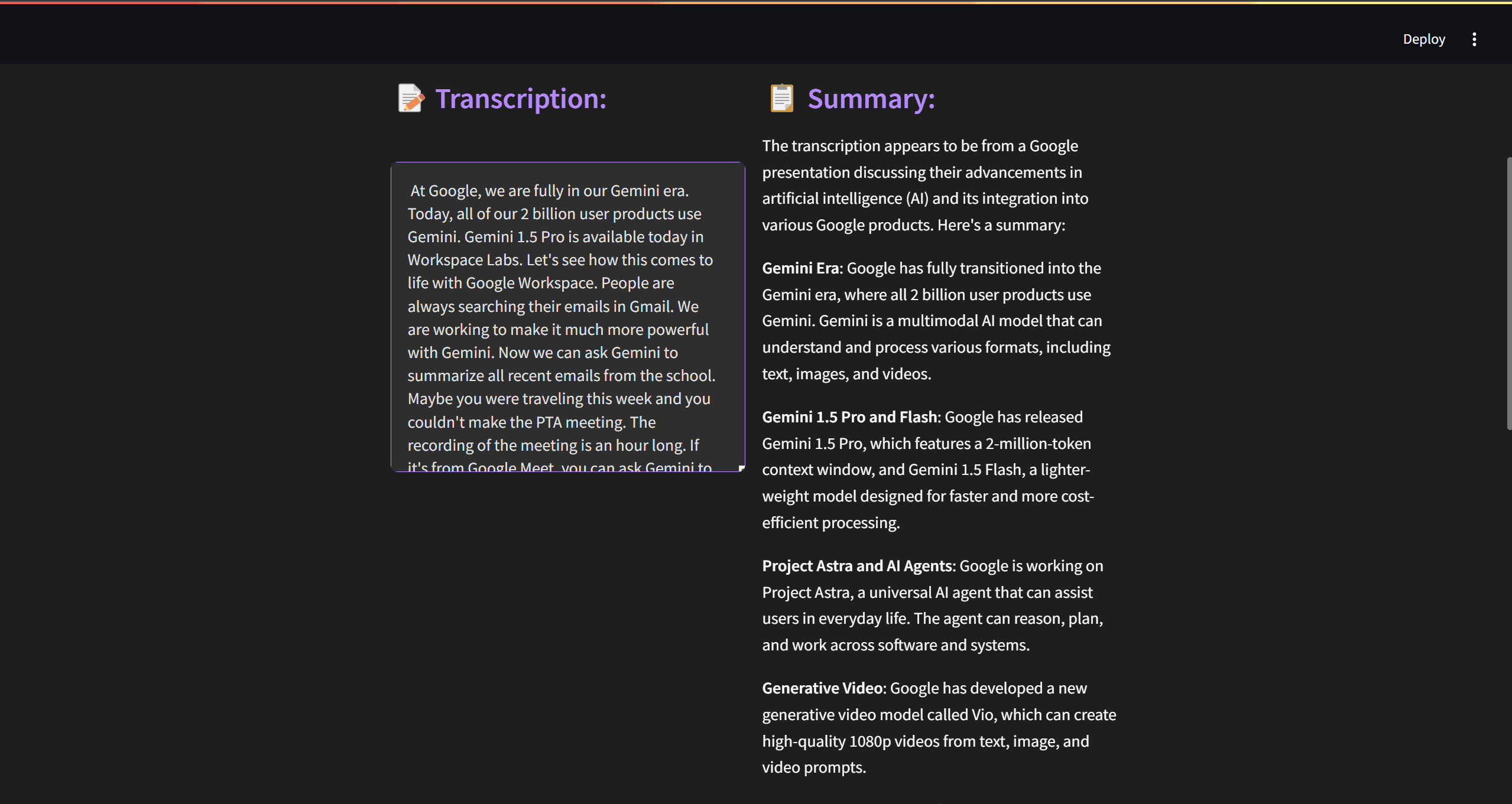
st.subheader("📝 Transcription:")
st.text_area(
"", value=transcription, height=300, max_chars=None, key="transcription_output"
)
st.session_state.transcription = transcription
os.unlink(temp_file_path)
except Exception as e:
st.error(f"❌ An error occurred: {str(e)}")
finally:
if "temp_file_path" in locals():
try:
os.unlink(temp_file_path)
except:
pass
if "audio_file_path" in locals():
try:
os.unlink(audio_file_path)
except:
pass
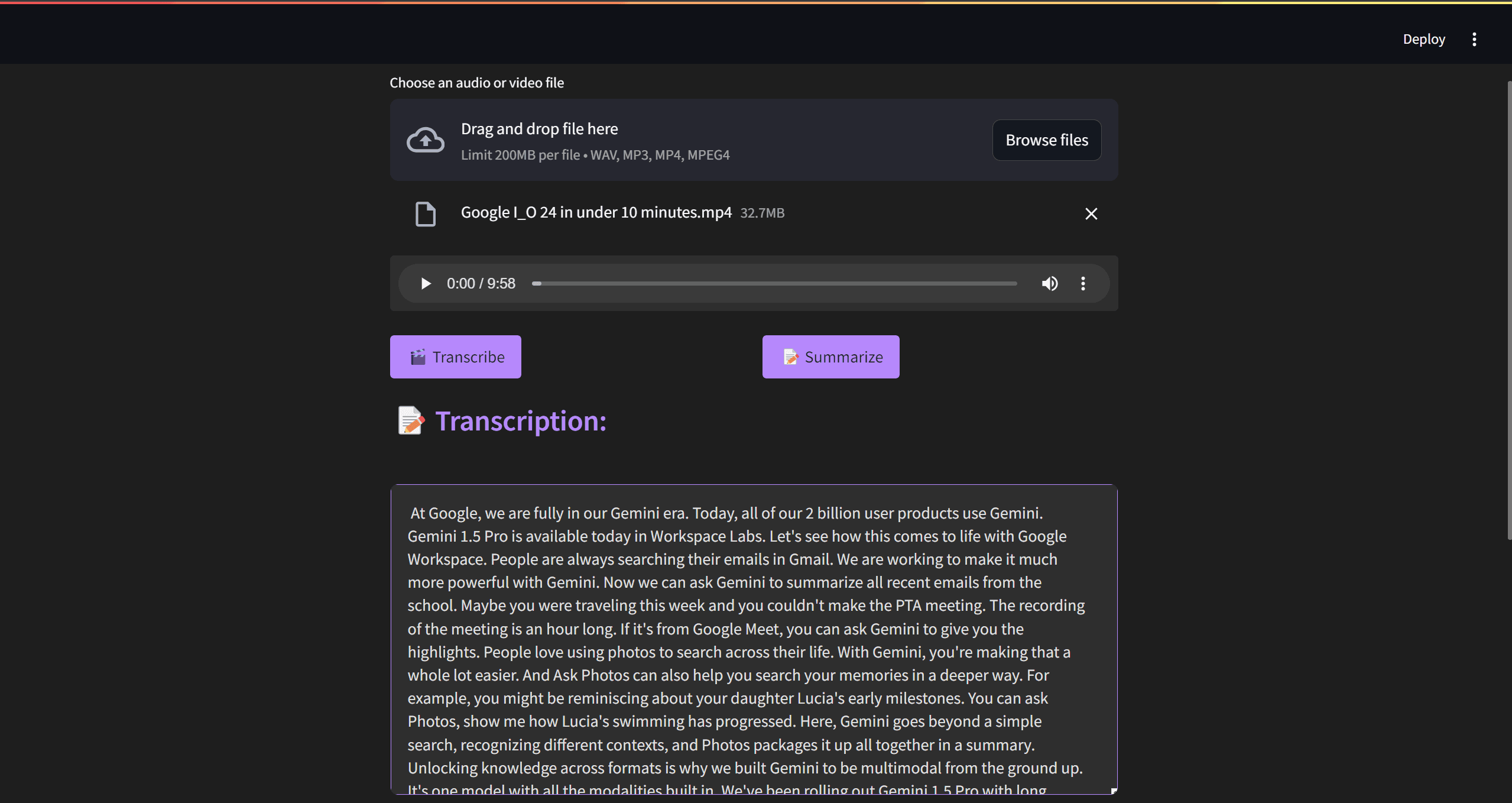
When the "Transcribe" button is clicked:
- Show a spinner while processing
- Write the uploaded file bytes to a temporary file
- If it's a video file, extract the audio and update the temporary file path
- Call
transcribe_audiowith the temporary file path to get the transcription - Display the transcription in a text area
- Store the transcription in
st.session_statefor later use in summarization - Delete the temporary files
- Handle and display any errors that occur during the process
Summarization
if summarize_button:
if "transcription" in st.session_state:
with st.spinner("Summarizing..."):
try:
response = client.chat.completions.create(
messages=[
{"role": "system", "content": "You are a helpful assistant that summarizes text."},
{
"role": "user",
"content": f"Please summarize the following transcription:\n\n{st.session_state.transcription}",
},
],
model="llama-3.2-90b-text-preview",
temperature=0.5,
)
summary = response.choices[0].message.content
with col_summary:
st.subheader("📋 Summary:")
st.markdown(summary)
except Exception as e:
st.error(f"❌ An error occurred during summarization: {str(e)}")
else:
st.warning("Please transcribe the audio/video first.")
When the "Summarize" button is clicked:
- Check if there is a transcription stored in
st.session_state - If yes, show a spinner while processing
- Call Groq's Text Summarization API with the transcription
- Display the summary in the right column
- Handle and display any errors
- If there is no stored transcription, show a warning message to transcribe first
Conclusion
And there you have it! A Streamlit app that transcribes and summarizes audio/video files using the Groq API. The transcription is performed using Groq's Speech-to-Text API, and the summary is generated using their Chat Completion API.
The code also demonstrates working with temporary files, extracting audio from video, and storing data in st.session_state for use across different parts of the app.
This is a great starting point to build upon and customize for your specific business needs. You could extend it to support more file types, add user authentication, store the transcriptions and summaries in a database, and much more!
Feel free to experiment, explore the Streamlit and Groq docs, and happy automating!