
- Published on
Navigating the World of ads.txt - How We Leveraged MongoDB and Selenium for Web Scraping
The Importance of Ads.txt in Today's Advertising World
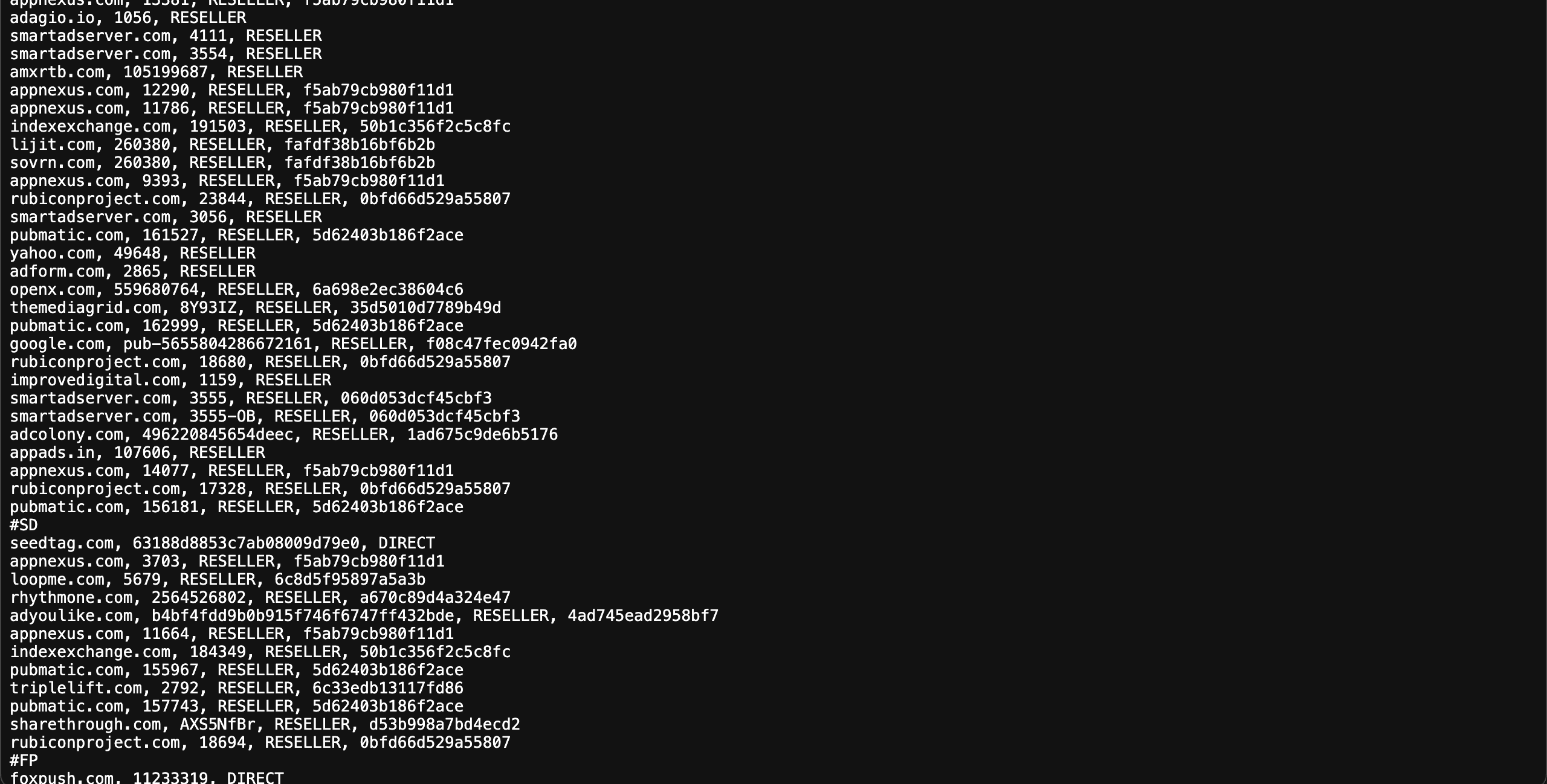
In the ever-evolving world of digital advertising, transparency is key. That's where ads.txt comes in. Created by the Interactive Advertising Bureau (IAB), ads.txt (Authorized Digital Sellers) is a simple yet powerful tool that helps fight ad fraud. It lets publishers publicly declare who's authorized to sell their ad space. This declaration builds trust and maintains integrity in the digital advertising ecosystem.
For us, accessing this data is crucial for several reasons:
- Keeping it Legit: We can make sure our ads are placed through authorized sellers, avoiding shady dealings.
- Understanding the Landscape: It gives us a peek into publisher partnerships and the broader advertising world.
- Smarter Spending: We can use this data to make informed decisions and get the most bang for our advertising buck.
Knowing the value of this data, we set out to automate the process of collecting and organizing it.
Our Mission: Taming Ads.txt Data with Automation
Our goal was simple: automatically gather ads.txt data from various publisher sites, organize it, and store it neatly in MongoDB. We knew it wouldn't be a walk in the park, but our team was up for the challenge. Here's our game plan:
- URL Collection: Start with a CSV file containing the URLs of publishers we're interested in.
- URL Cleanup: Make sure all URLs are correctly formatted to avoid missing out on data.
- Ads.txt Retrieval: Use Selenium to visit each URL and grab the ads.txt content.
- Data Wrangling: Extract the important information and structure it.
- MongoDB Storage: Store the structured data in MongoDB for easy access and querying.
Prepping the URLs: A Little Spring Cleaning
Before diving into the technical nitty-gritty, we had to ensure our list of publisher URLs was squeaky clean. URLs can be messy – missing "http" or "https", extra bits at the end, you name it. So, we wrote a function to tidy things up:
from urllib.parse import urlparse, urlunparse
def correct_url(url):
parsed_url = urlparse(url)
scheme = parsed_url.scheme if parsed_url.scheme else 'https'
netloc = parsed_url.netloc if parsed_url.netloc else parsed_url.path.split('/')[0]
if not parsed_url.netloc:
path = '/' + '/'.join(parsed_url.path.split('/')[1:])
else:
path = parsed_url.path
if path.endswith('.txt'):
path = path
else:
if not path.endswith('/'):
path += '/'
path += 'ads.txt'
corrected_url = urlunparse((scheme, netloc, path, '', '', ''))
return corrected_url
This function standardizes each URL, pointing it directly to the ads.txt file. This crucial step prevented hiccups later on.
Fetching the Data: Selenium to the Rescue
With our polished URLs, we used Selenium to fetch the ads.txt content. Selenium's strength lies in handling dynamic web pages, making it perfect for this task.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import re
def fetch_ads_txt(url):
options = Options()
options.headless = True
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36") # Mimic a real browser
driver = webdriver.Chrome(options=options)
try:
driver.get(url)
content = driver.find_element(By.TAG_NAME, "pre").text
content_lines = re.split(r'\r\n|\n', content.strip())
return url, content_lines
except Exception as e:
print(f"Failed to retrieve {url}: {e}")
return url, None
finally:
driver.quit()
Running Selenium headlessly (without a browser window popping up) made the process faster and more efficient. We also incorporated a User-agent to mimic a regular browser.
Organizing the Data: Making Sense of it All
After retrieving the ads.txt content, we needed to parse and structure it. Although ads.txt files have a straightforward format, they can contain multiple entries and comments. Our goal: extract the good stuff and discard the rest.
def parse_ads_txt(content_lines):
records = []
for line in content_lines:
if line.startswith('#') or not line.strip():
continue
fields = line.split(',')
if len(fields) >= 3:
records.append({
'domain': fields[0].strip(),
'publisher_id': fields[1].strip(),
'relationship': fields[2].strip(),
'cert_authority_id': fields[3].strip() if len(fields) > 3 else None
})
return records
This function neatly extracts the domain, publisher ID, relationship, and optional certification authority ID, creating a structured list of records.
Storing the Data: MongoDB – Our Data Haven
Finally, we stored the parsed data in MongoDB. Its flexibility and scalability made it a perfect fit.
from pymongo import MongoClient
import os
def store_in_mongodb(records, db_name='ads_txt', collection_name='records'):
mongodb_uri = os.getenv("MONGODB_URI") # Fetching database credentials
if not mongodb_uri:
raise ValueError("MONGODB_URI environment variable not set.")
try:
client = MongoClient(mongodb_uri)
db = client[db_name]
collection = db[collection_name]
if records:
collection.insert_many(records)
except Exception as e:
print(f"Failed to connect or insert data: {e}")
finally:
if client:
client.close()
We improved the MongoDB connection to use environment variables and also added basic error handling.
Reaping the Rewards: How This Helped Our Business
Automating the ads.txt data collection process brought significant benefits:
- Ad Integrity Assurance: By verifying that our ads are sold through legitimate channels, we minimize the risk of ad fraud and protect our brand.
- Optimized Ad Budget: Clear insights into ad placements empower us to allocate our budget effectively, maximizing our return on investment.
- Enhanced Reporting: Detailed ads.txt reports provide transparency to our clients, strengthening partnerships and fostering trust.
Looking Ahead: Future Improvements
We're always looking for ways to improve. Here's what we have in mind:
- Real-time Updates: Keeping our ads.txt data constantly up-to-date.
- Deeper Analysis: Using advanced analytics to uncover hidden insights.
- Visual Dashboard: Creating a user-friendly dashboard to visualize data and provide actionable insights.
Wrapping Up: A Rewarding Adventure
Our exploration of web scraping with Selenium and MongoDB was challenging yet incredibly rewarding. By automating the ads.txt data pipeline, we've streamlined our operations and empowered our team to innovate. We're excited to see where this journey takes us next. Stay tuned for more updates as we continue to push the boundaries of digital advertising and data management. Happy scraping!